


基于嵌入式CPU+GPU异构平台的遥感图像滤波加速
doi: 10.11728/cjss2024.01.2023-0033
-
 谭鹏源 男, 1996年9月出生于广西壮族自治区钦州市. 现为中国科学院国家空间科学中心硕士研究生, 主要研究方向为遥感图像并行处理. E-mail: tanpengyuan19@mails.ucas.ac.cn
谭鹏源 男, 1996年9月出生于广西壮族自治区钦州市. 现为中国科学院国家空间科学中心硕士研究生, 主要研究方向为遥感图像并行处理. E-mail: tanpengyuan19@mails.ucas.ac.cn -
 薛长斌 男, 1972年5月出生于辽宁省锦州市. 现为中国科学院国家空间科学中心研究员, 博士生导师, 主要研究方向为空间在轨精密过程控制技术、星上数据管理技术及航天系统工程等. E-mail: xuechangbin@nssc.ac.cn
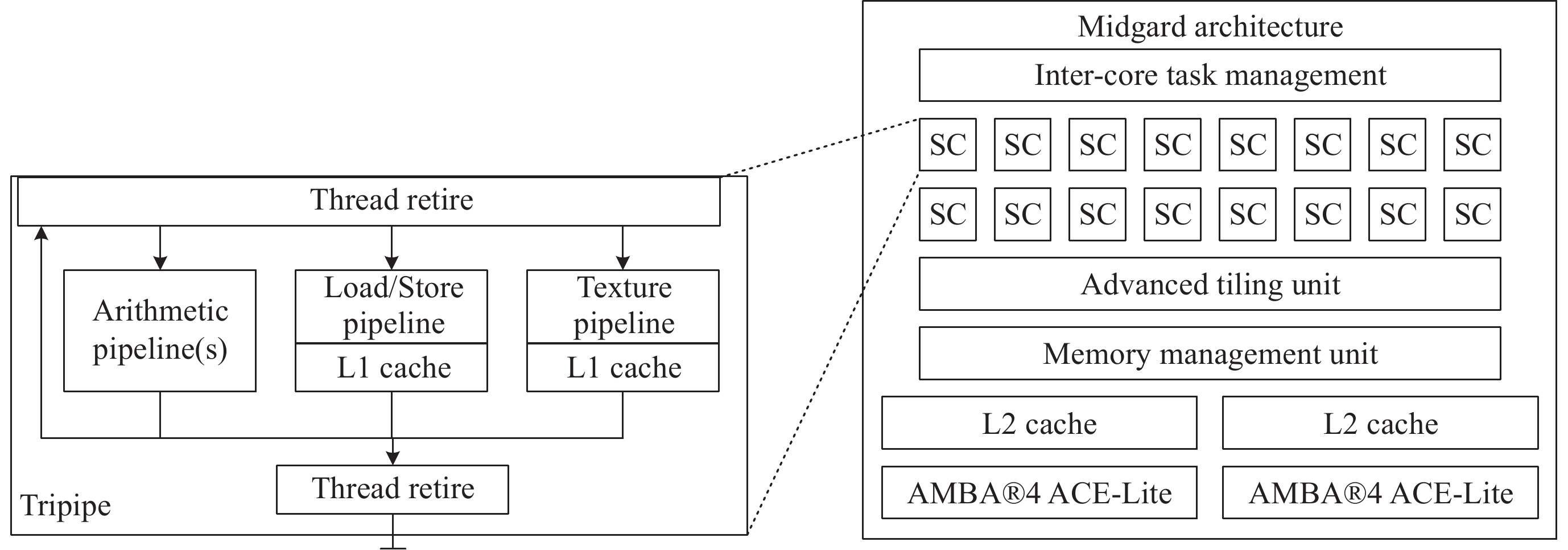
薛长斌 男, 1972年5月出生于辽宁省锦州市. 现为中国科学院国家空间科学中心研究员, 博士生导师, 主要研究方向为空间在轨精密过程控制技术、星上数据管理技术及航天系统工程等. E-mail: xuechangbin@nssc.ac.cn
作者简介:
通讯作者:
Acceleration of Remote Sensing Image Filtering Based on Embedded CPU+GPU Heterogeneous Platform
-
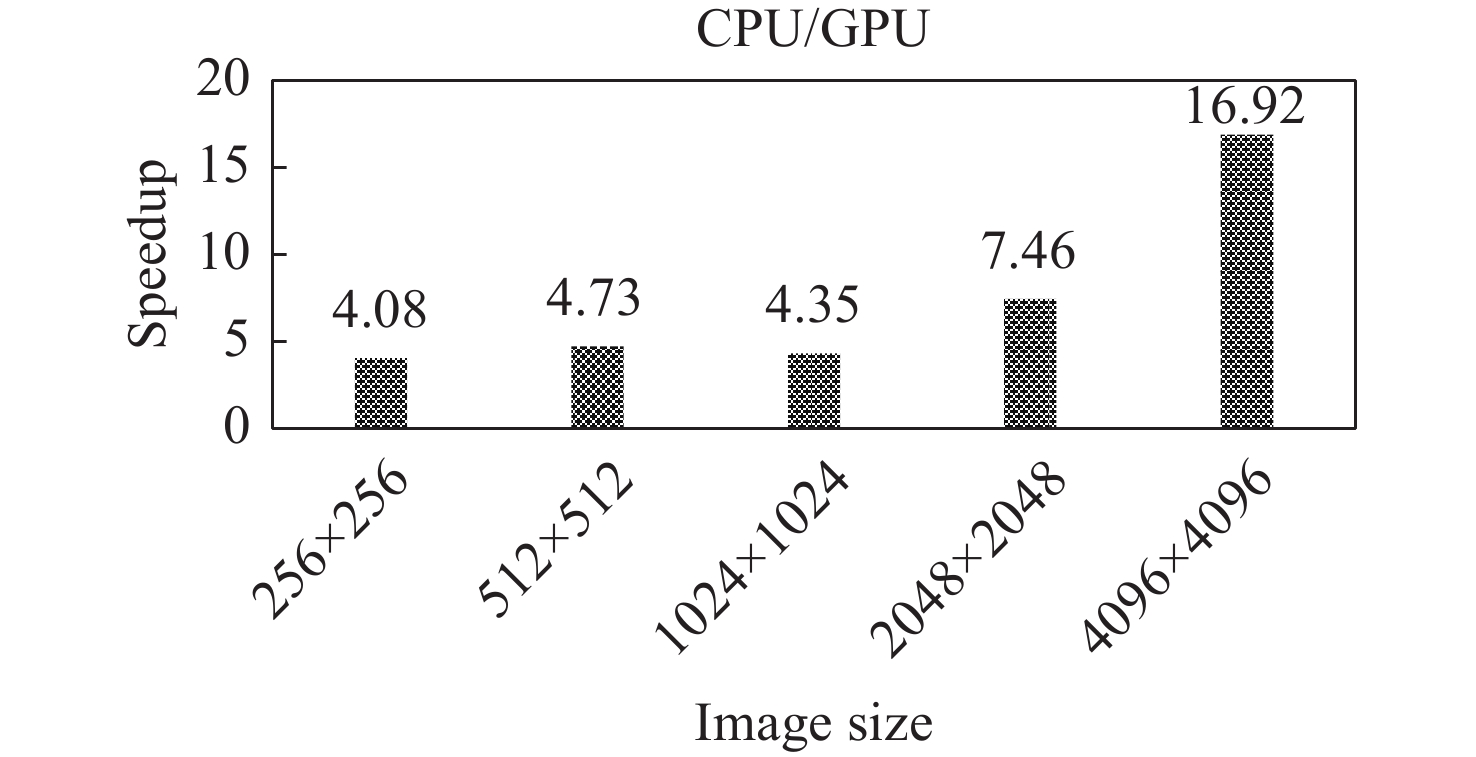
摘要: 针对遥感图像在轨实时处理提出一种基于嵌入式CPU + GPU异构平台的遥感图像滤波加速设计方法. 以加速拉普拉斯滤波为例, 利用GPU的并行计算特点, 通过数据划分及数据映射的方法对算法进行并行设计; 利用GPU的向量单元和缓存等硬件资源, 通过采取向量化和向量重组以及工作组调优方法进一步提高了算法的运行速度. 在嵌入式开发板上验证了加速设计的可行性和高效性. 实验结果表明, 相比于单CPU的串行实现, 在增加GPU并行处理后的拉普拉斯滤波获得了4.08~16.92倍的加速比. 进一步利用GPU硬件资源优化性能后, 加速比可达15.38~56.41倍.Abstract: A method is proposed for accelerating remote sensing image filtering in real-time using an embedded CPU + GPU heterogeneous platform for satellite-based image processing. the algorithm was initially parallelized through data division and mapping, leveraging the parallel computing capabilities of the GPU. Subsequently, hardware resources like the vector unit and cache of the GPU were employed to enhance algorithm speed through vectorization, vector permutation, and workgroup tuning. The feasibility and efficiency of this accelerated design were validated on an embedded development board. The experiments demonstrate a speedup ranging from 4.08 to 16.92 times when incorporating GPU parallel processing, compared to the serial implementation on a single CPU. Further optimization using GPU hardware resources can push the speedup to 15.38 to 56.41 times.
-
Key words:
- Embedded GPU /
- Remote sensing image filtering /
- OpenCL /
- Vectorization /
- Vector permutation
-
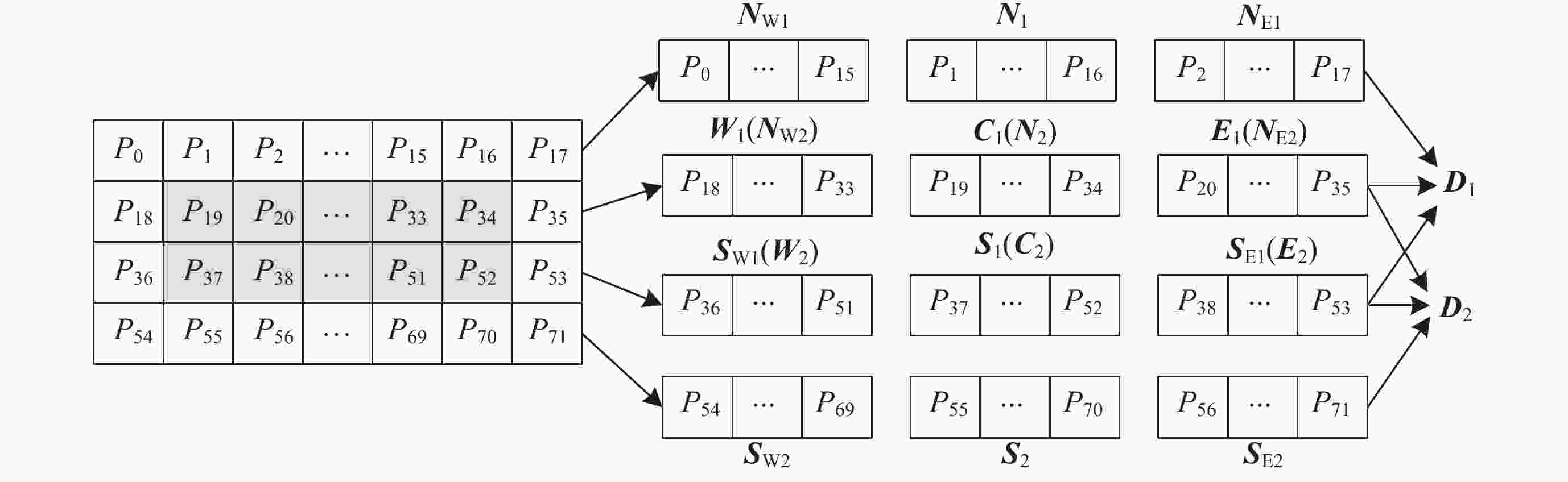
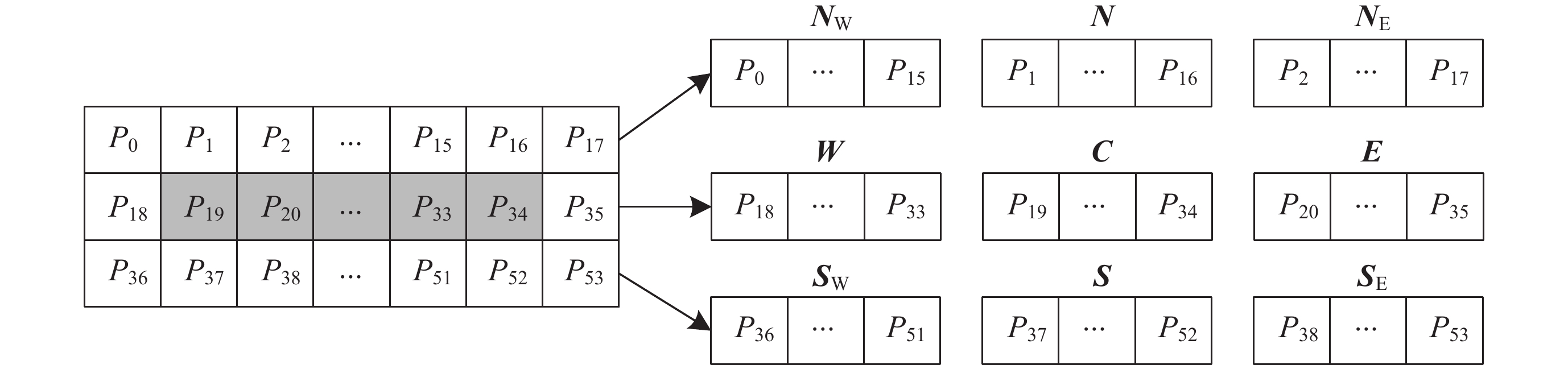
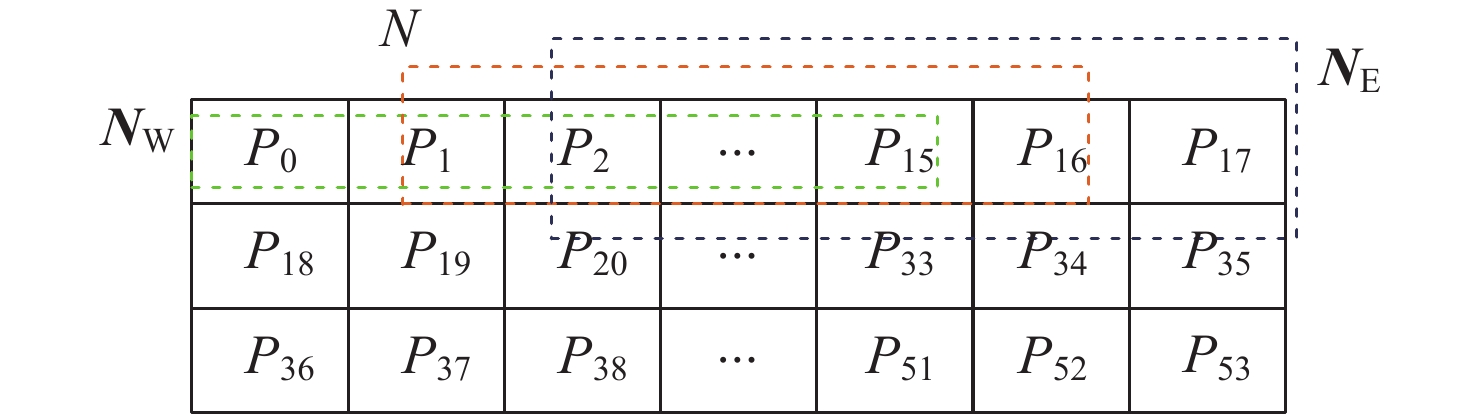
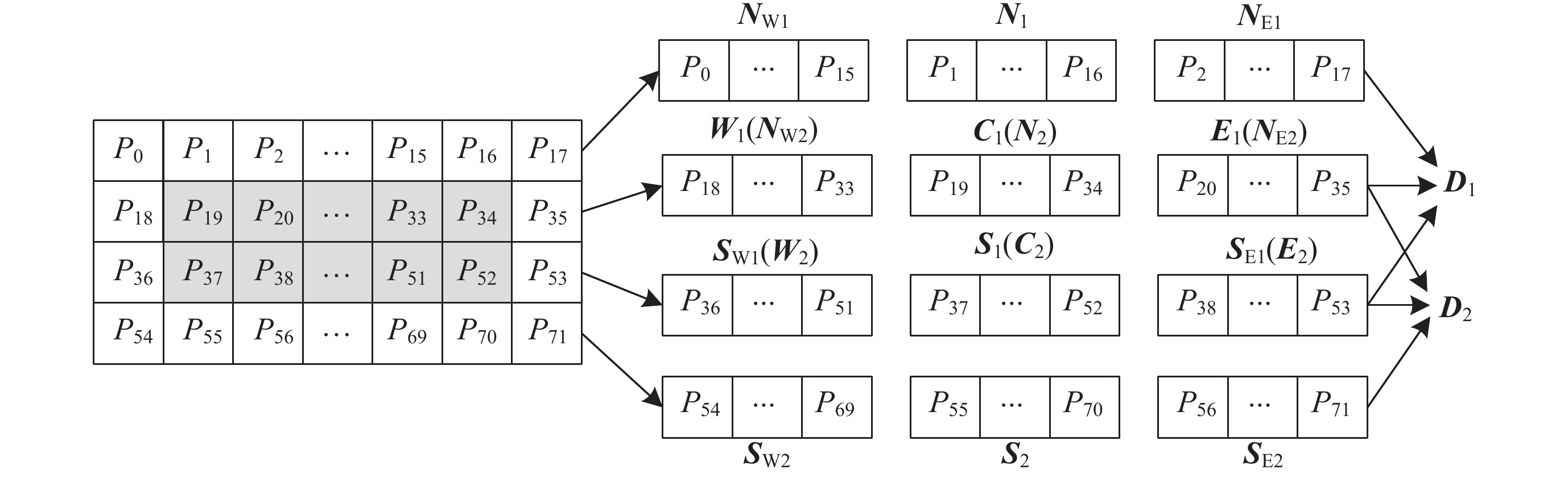
图 7 相邻行目标向量的计算存在重复使用的数据
Figure 7. Calculation of two target vectors in adjacent rows involves duplicated data
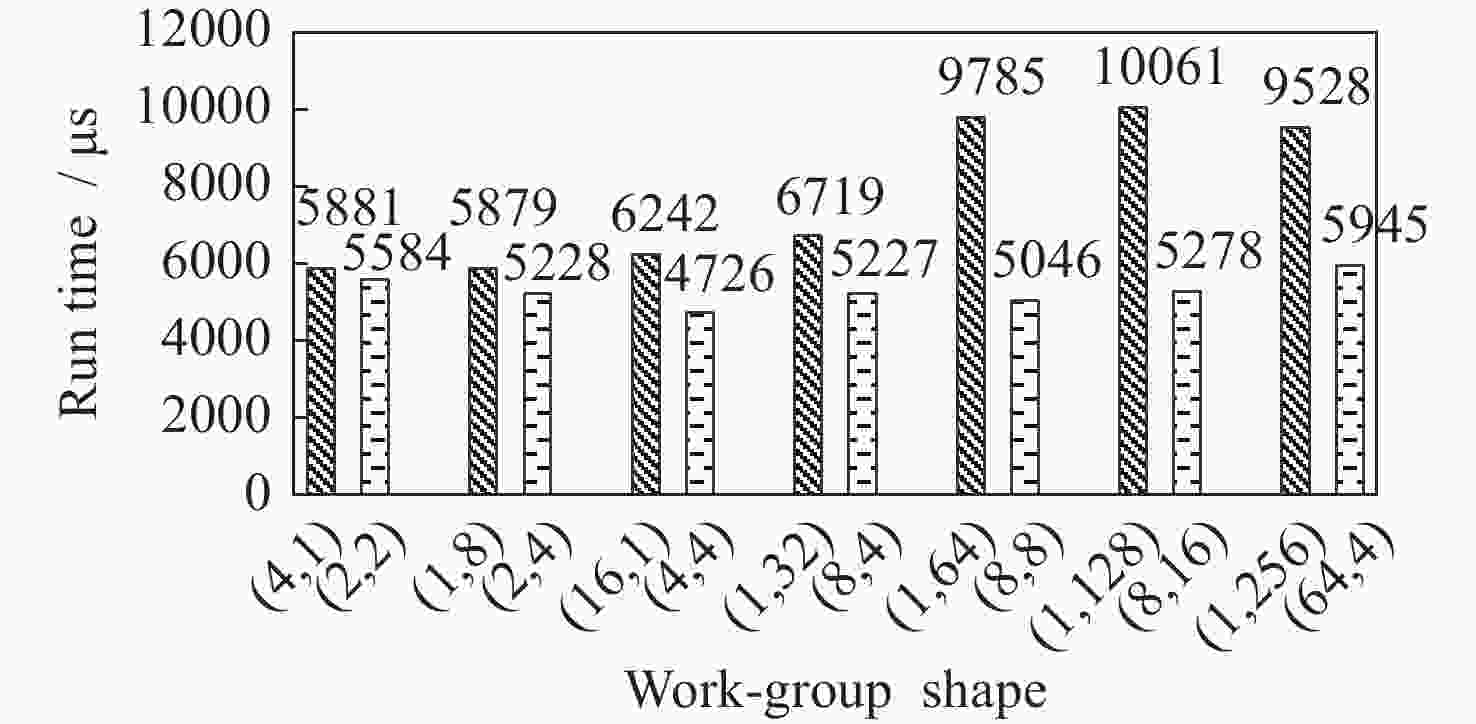
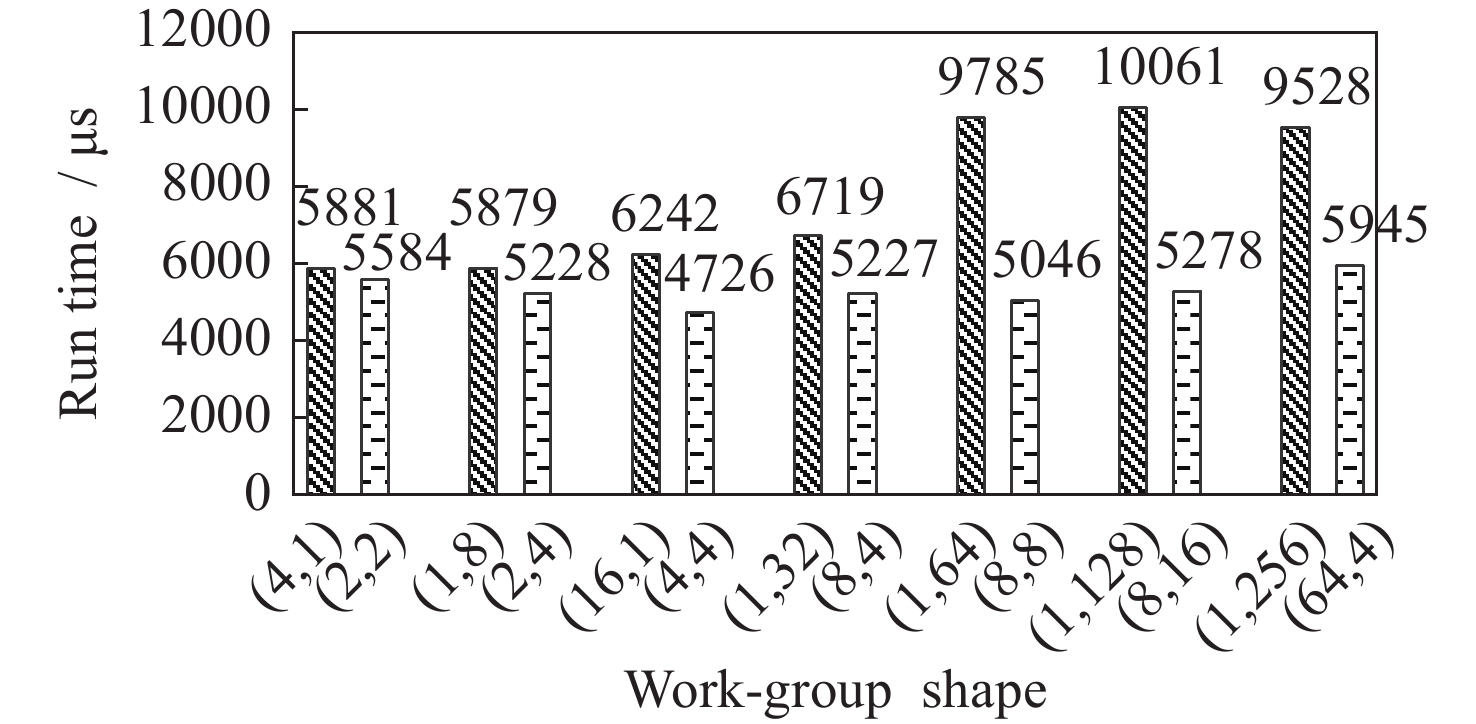
图 8 不同工作组大小下最坏形状(深色条纹)和最优形状(浅色条纹)对应的内核执行时间
Figure 8. Kernel execution times corresponding to worst (dark stripes) and optimal (light stripes) shapesfor different workgroup sizes
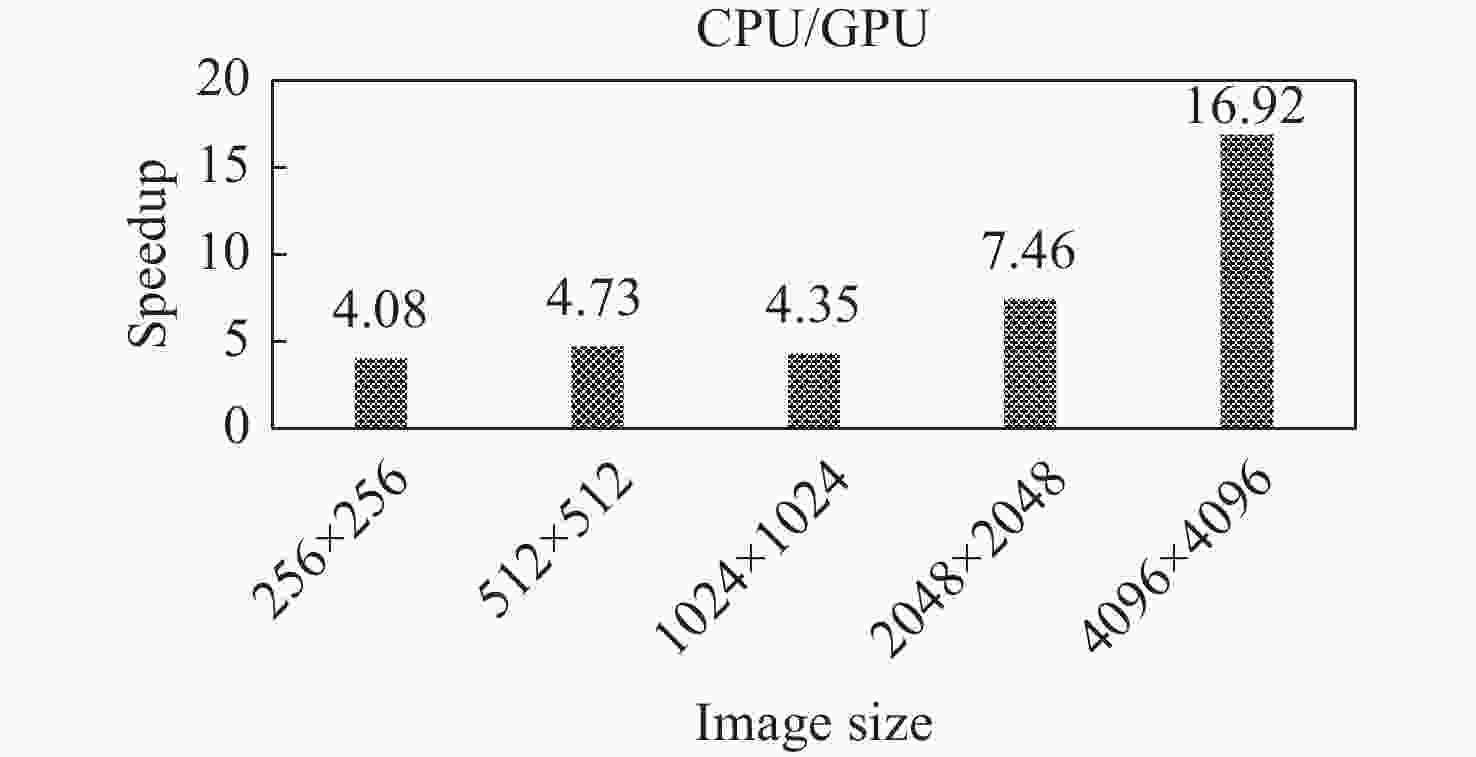
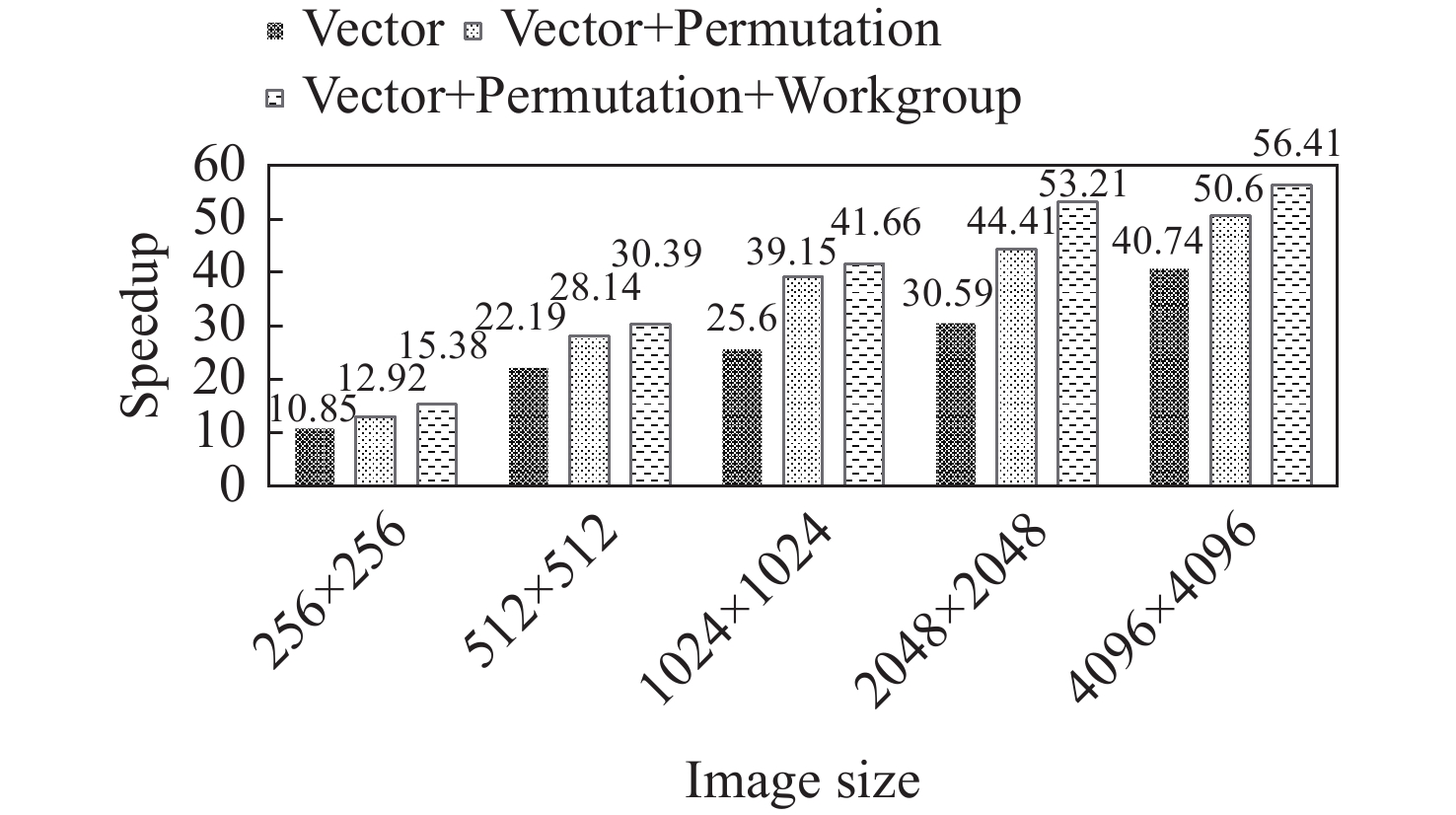
图 9 拉普拉斯滤波GPU版本相对于CPU版本的加速比
Figure 9. Speedup of the Laplacian filtering GPU version relative to its CPU counterpart
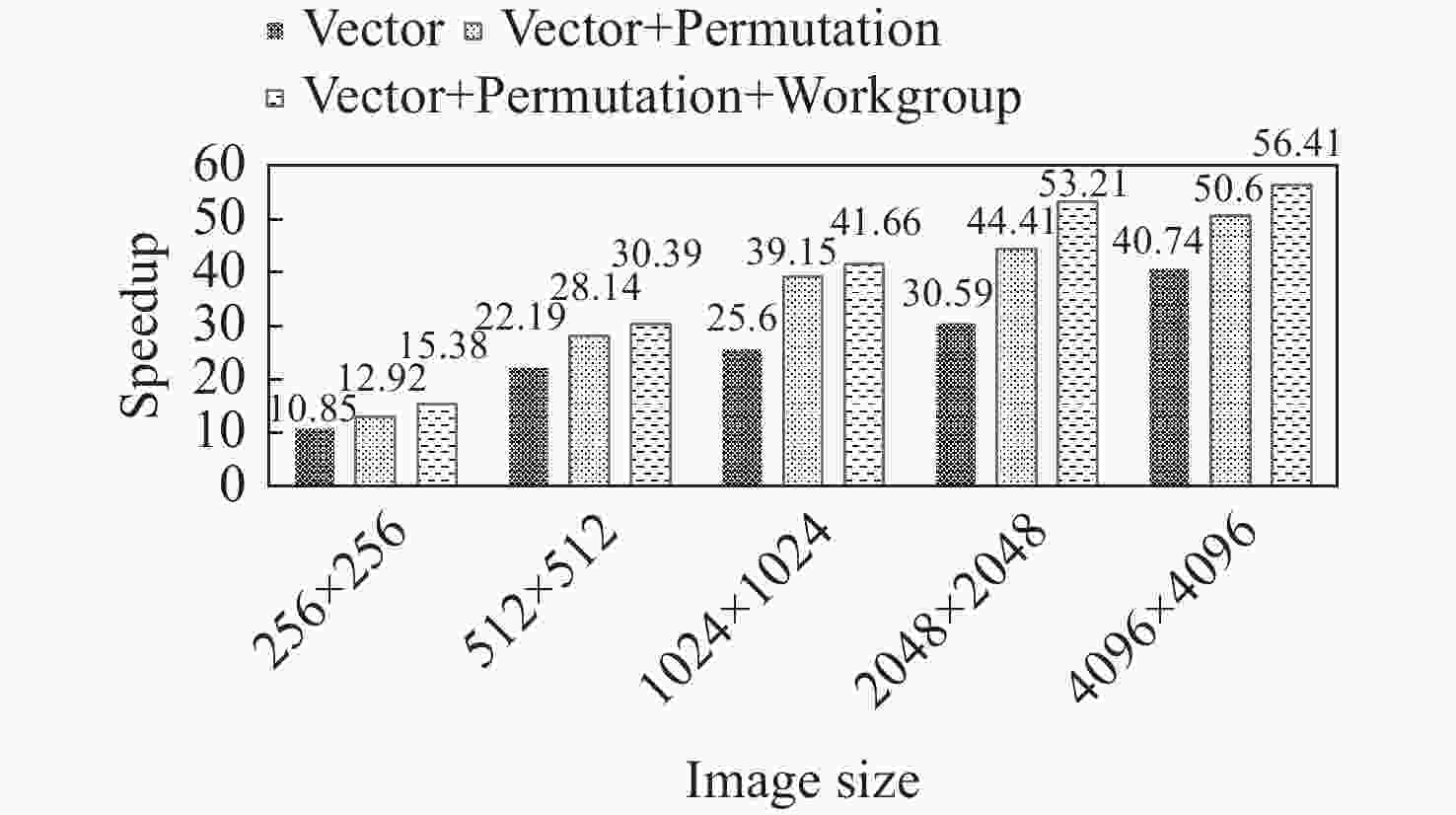
图 10 不同优化方法在GPU上获得的性能
Figure 10. Performance obtained on the GPU through various optimization methods
-
[1] 韦玉春, 汤国安, 杨昕, 等. 遥感数字图像处理教程[M]. 北京: 科学出版社, 2007: 174-184WEI Yuchun, TANG Guoan, YANG Xin, et al. Remote Sensing Digital Image Processing Course[M]. Beijing: Science Press, 2007: 174-184 [2] KOSMIDIS L, RODRIGUEZ I, JOVER-ALVAREZ A, et al. GPU4S: Major project outcomes, lessons learnt and way forward[C]//2021 Design, Automation & Test in Europe Conference & Exhibition (DATE). Grenoble, France: IEEE, 2021: 1314-1319 [3] XIAO H, GUO B Y, ZHANG H Y, et al. A parallel algorithm of image mean filtering based on OpenCL[J]. IEEE Access, 2021, 9: 65001-65016 doi: 10.1109/ACCESS.2021.3068772 [4] XIAO H, XIAO S Y, MA G, et al. Image Sobel edge extraction algorithm accelerated by OpenCL[J]. The Journal of Supercomputing, 2022, 78(14): 16236-16265 doi: 10.1007/s11227-022-04404-8 [5] PANG Y L, JIANG S, CHENG B W, et al. Design and implement of median filter toward remote sensing images based on FPGA[C]//2021 IEEE 14th International Conference on ASIC (ASICON). Kunming, China: IEEE, 2021: 1-4 [6] HARRIS P. The Mali GPU: An Abstract Machine, Part 3-The Midgard Shader Core[OL]. (2014-03-12)[2023-02-10]. https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/the-mali-gpu-an-abstract-machine-part-3--the-midgard-shader-core [7] Khronos OpenCL Working Group. The OpenCL Specification V1.2[EB/OL]. (2011-11-14)[2013-02-10]. https://registry.khronos.org/OpenCL/specs/opencl-1.2.pdf [8] 周浔. 工业射线图像增强算法的研究[D]. 广州: 华南理工大学, 2020ZHOU Xun. Research on Industrial Ray Image Enhancement Algorithm[D]. Guangzhou: South China University of Technology, 2020 [9] SEO S, LEE J, JO G, et al. Automatic OpenCL work-group size selection for multicore CPUs[C]//Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques. Edinburgh, UK: IEEE, 2013: 387-397 [10] USAMENTIAGA R. Real-time filtering on parallel SIMD architectures for automated quality inspection[J]. Journal of Real-Time Image Processing, 2021, 18(1): 127-141 doi: 10.1007/s11554-020-00954-3 [11] LI K, YUAN L, ZHANG Y Q, et al. Reducing redundancy in data organization and arithmetic calculation for stencil computations[C]//Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. St. Louis, Missouri: ACM, 2021: 84 [12] 董钰山. 面向SMP的模板计算访存优化研究[D]. 长沙: 国防科学技术大学, 2015DONG Yushan. Optimizations of Memory-access for Stencil Computations on Shared-memory Multi-core Processor[D]. Changsha: National University of Defense Technology, 2015 [13] JIANG S Q, RAN L H, CAO T, et al. Profiling and optimizing deep learning inference on mobile GPUs[C]//Proceedings of the 11th ACM SIGOPS Asia-Pacific Workshop on Systems. Tsukuba, Japan: ACM, 2020: 75-81 -
-
 下载:
下载:
计量
- 文章访问数: 1070
- HTML全文浏览量: 415
- PDF下载量: 83
-
被引次数:
0(来源:Crossref)
0(来源:其他)

