| Citation: | CHEN Yuhan, CHEN Yu, DENG Li, CHEN Shi. Video Super-resolution Method for Spacecraft Approaching and Detecting Asteroids (in Chinese). Chinese Journal of Space Science, 2026, 46(1): 150-162 doi: 10.11728/cjss2026.01.2025-0002

|
| [1] |
DONG C, LOY C C, HE K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307 doi: 10.1109/TPAMI.2015.2439281
|
| [2] |
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deepconvolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. LasVegas: IEEE, 2016: 1646-1654
|
| [3] |
YANG J C, HUANG T. Image super-resolution: Historical overview and future challenges[M]//MILANFAR P. Super-Resolution Imaging. Boca Raton: CRC Press, 2017: 1-34
|
| [4] |
LIU H Y, RUAN Z B, ZHAO P, et al. Video super-resolution based on deep learning: a comprehensive survey[J]. Artificial Intelligence Review, 2022, 55(8): 5981-6035 doi: 10.1007/s10462-022-10147-y
|
| [5] |
LEPCHA D C, GOYAL B, DOGRA A, et al. Image super-resolution: a comprehensive review, recent trends, challenges and applications[J]. Information Fusion, 2022, 91: 230-260 doi: 10.1016/j.inffus.2022.10.007
|
| [6] |
HA V K, REN J C, XU X Y, et al. Deep learning based single image super-resolution: A survey[C]//9th Advances in Brain Inspired Cognitive Systems. Cham: Springer, 2018: 106-119
|
| [7] |
WANG Z H, CHEN J, HOI S C H. Deep learning for image super-resolution: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3365-3387 doi: 10.1109/TPAMI.2020.2982166
|
| [8] |
JENEFA A, KURIAKOSE B M, EDWARD N V, et al. EDSR: Empowering super-resolution algorithms with high-quality DIV2K images[J]. Intelligent Decision Technologies, 2023, 17(4): 1249-1263 doi: 10.3233/IDT-230218
|
| [9] |
NAGANO Y, KIKUTA Y. SRGAN for super-resolving low-resolution food images[C]//Proceedings of the Joint Workshop on Multimedia for Cooking and Eating Activities and Multimedia Assisted Dietary Management. New York: ACM, 2018: 33-37
|
| [10] |
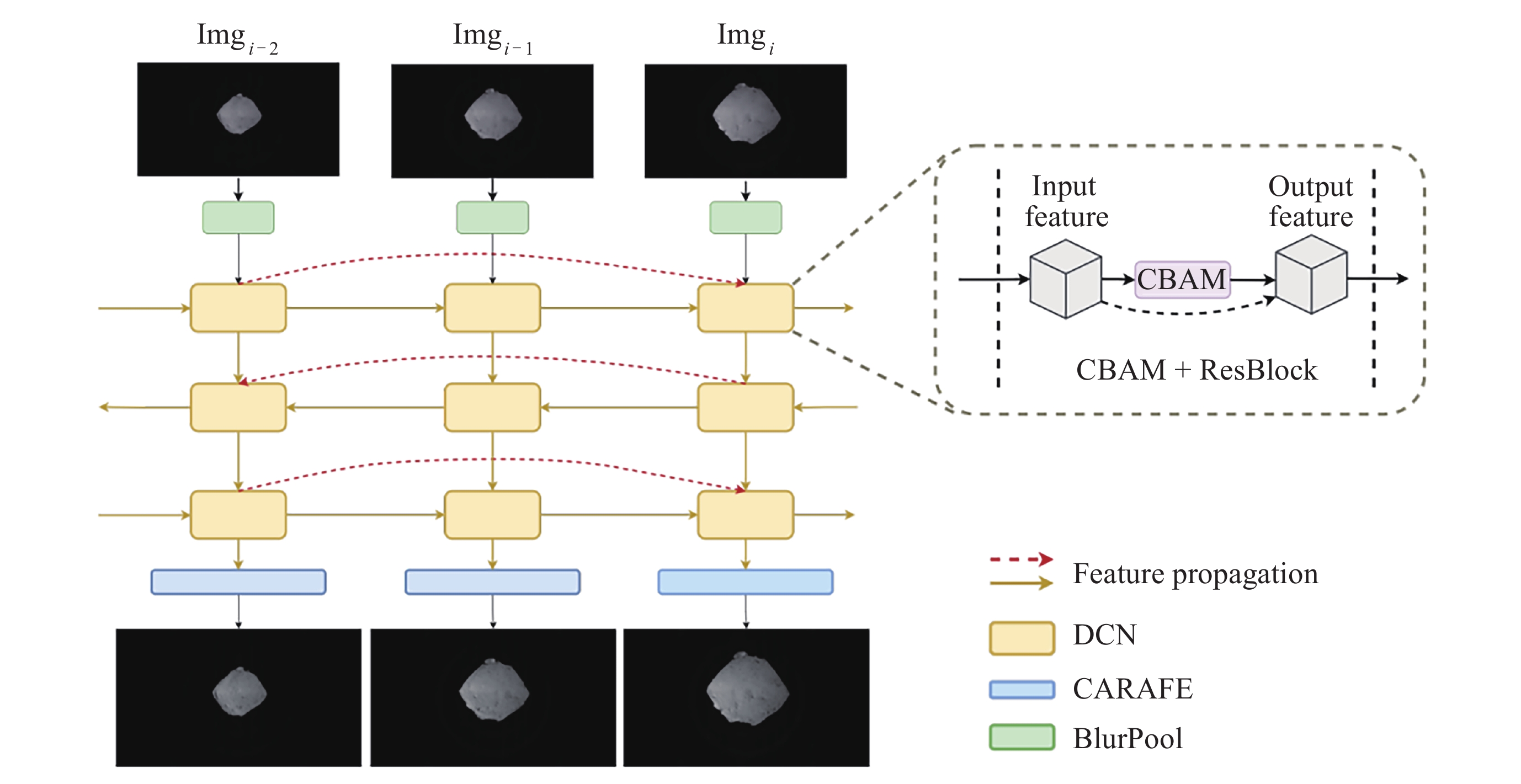
WANG X T, CHAN K C K, YU K, et al. EDVR: Video restoration with enhanced deformable convolutional networks[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach: IEEE, 2019: 1954-1963
|
| [11] |
TIAN Y P, ZHANG Y L, FU Y, et al. TDAN: Temporally-Deformable Alignment Network for video super-resolution[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 3357-3366
|
| [12] |
GOPALAKRISHNAN S, CHOUDHURY A. A “deep” review of video super-resolution[J]. Signal Processing: Image Communication, 2024, 129: 117175 doi: 10.1016/j.image.2024.117175
|
| [13] |
CHAN K C K, ZHOU S C, XU X Y, et al. BasicVSR++: Improving video super-resolution with enhanced propagation and alignment[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 5962-5971
|
| [14] |
RABINOWITZ D L. Detection of Earth-approaching asteroids in near real time[J]. Astronomical Journal, 1991, 101(4): 1518-1529 doi: 10.1086/115785
|
| [15] |
NIU Z Y, ZHONG G A, YU H. A review on the attention mechanism of deep learning[J]. Neurocomputing, 2021, 452: 48-62 doi: 10.1016/j.neucom.2021.03.091
|
| [16] |
GUO M H, XU T X, LIU J J, et al. Attention mechanisms in computer vision: a survey[J]. Computational Visual Media, 2022, 8(3): 331-368 doi: 10.1007/s41095-022-0271-y
|
| [17] |
SOYDANER D. Attention mechanism in neural networks: where it comes and where it goes[J]. Neural Computing and Applications, 2022, 34(16): 13371-13385 doi: 10.1007/s00521-022-07366-3
|
| [18] |
HU J, SHEN L, SUN G, et al. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141
|
| [19] |
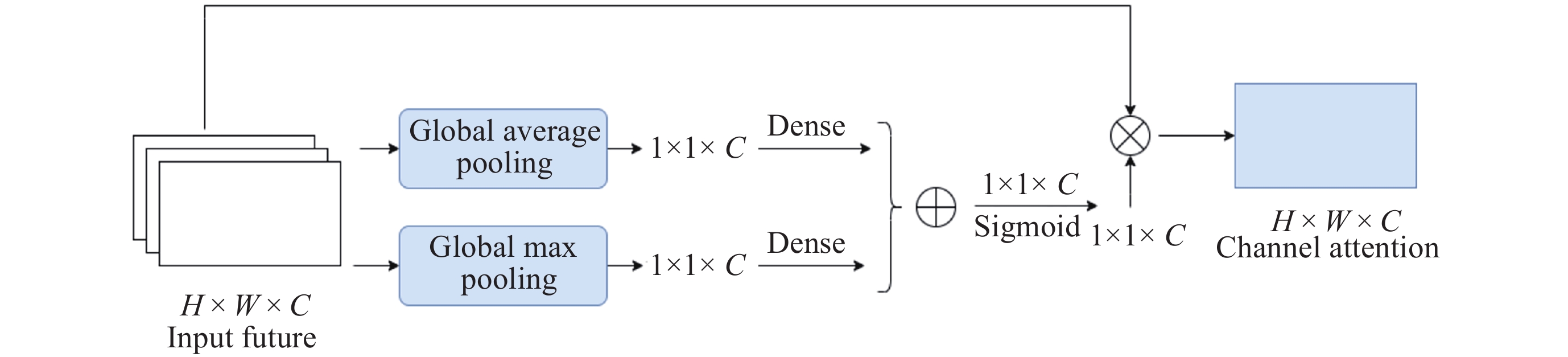
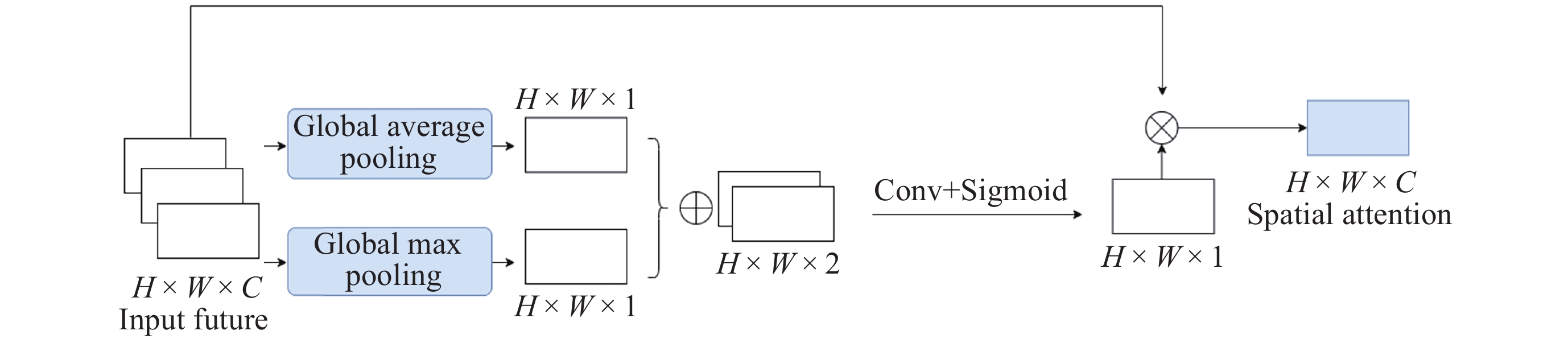
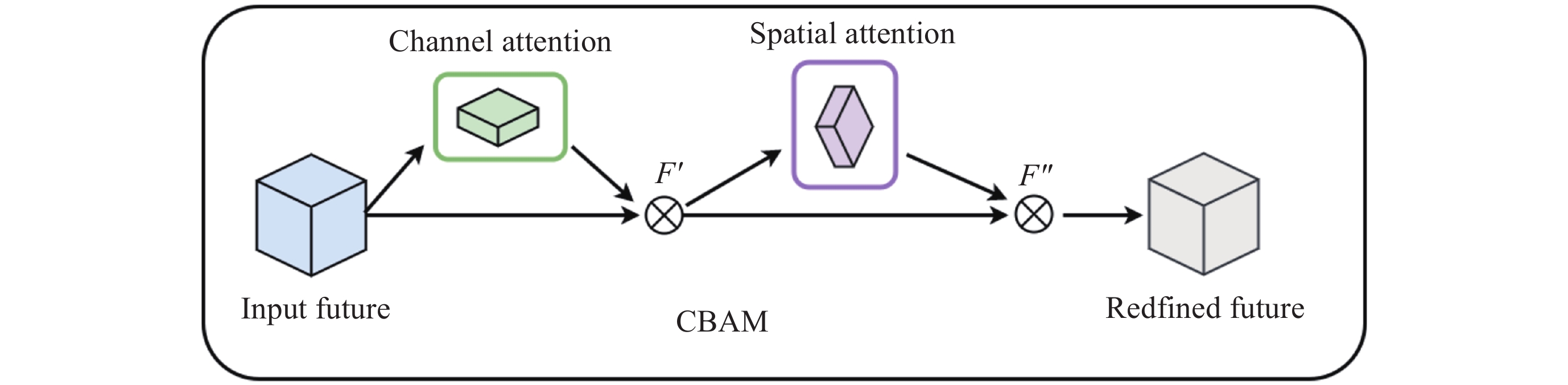
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the 15th European Conference. Cham: Springer, 2018: 3-19
|
| [20] |
WEN W L, REN W Q, SHI Y H, et al. Video super-resolution via a spatio-temporal alignment network[J]. IEEE Transactions on Image Processing, 2022, 31: 1761-1773 doi: 10.1109/TIP.2022.3146625
|
| [21] |
SHI S W, GU J J, XIE L B, et al. Rethinking alignment in video super-resolution transformers[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans: Curran Associates Inc., 2022: 2615
|
| [22] |
CABALLERO J, LEDIG C, AITKEN A, et al. Real-time video super-resolution with spatio-temporal networks and motion compensation[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2848-2857
|
| [23] |
WANG L G, GUO Y L, LIN Z P, et al. Learning for video super-resolution through HR optical flow estimation[C]//14th Asian Conference on Computer Vision. Cham: Springer, 2019: 514-529
|
| [24] |
XUE T F, CHEN B A, WU J J, et al. Video enhancement with task-oriented flow[J]. International Journal of Computer Vision, 2019, 127(8): 1106-1125 doi: 10.1007/s11263-018-01144-2
|
| [25] |
SAJJADI M S M, VEMULAPALLI R, BROWN M. Frame-recurrent video super-resolution[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6626-6634
|
| [26] |
JO Y, OH S W, KANG J, et al. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 3224-3232
|
| [27] |
HASSANIN M, ANWAR S, RADWAN I, et al. Visual attention methods in deep learning: An in-depth survey[J]. Information Fusion, 2024, 108: 102417 doi: 10.1016/j.inffus.2024.102417
|
| [28] |
CORDONNIER J B, LOUKAS A, JAGGI M. On the relationship between self-attention and convolutional layers[C]//International Conference on Learning Representations. Addis Ababa: OpenReview. net, 2019
|
| [29] |
ZHU X Z, HU H, LIN S, et al. Deformable convNets v2: More deformable, better results[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9300-9308
|
| [30] |
Wang H, Su D, Liu C, et al. Deformable Non-Local Network for VideoSuper-Resolution[J]. IEEE Access, 2019, 7: 177734-177744 doi: 10.1109/ACCESS.2019.2958030
|
| [31] |
YING X Y, WANG L G, WANG Y Q, et al. Deformable 3D convolution for video super-resolution[J]. IEEE Signal Processing Letters, 2020, 27: 1500-1504 doi: 10.1109/LSP.2020.3013518
|
| [32] |
WANG W, DAI J, CHEN Z, et al. InternImage: Exploring large-scale vision foundation models with deformable convolutions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 14408-14419.
|
| [33] |
XIONG Y W, LI Z Q, CHEN Y T, et al. Efficient deformable convNets: Rethinking dynamic and sparse operator for vision applications[C]//Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5652-5661
|
| [34] |
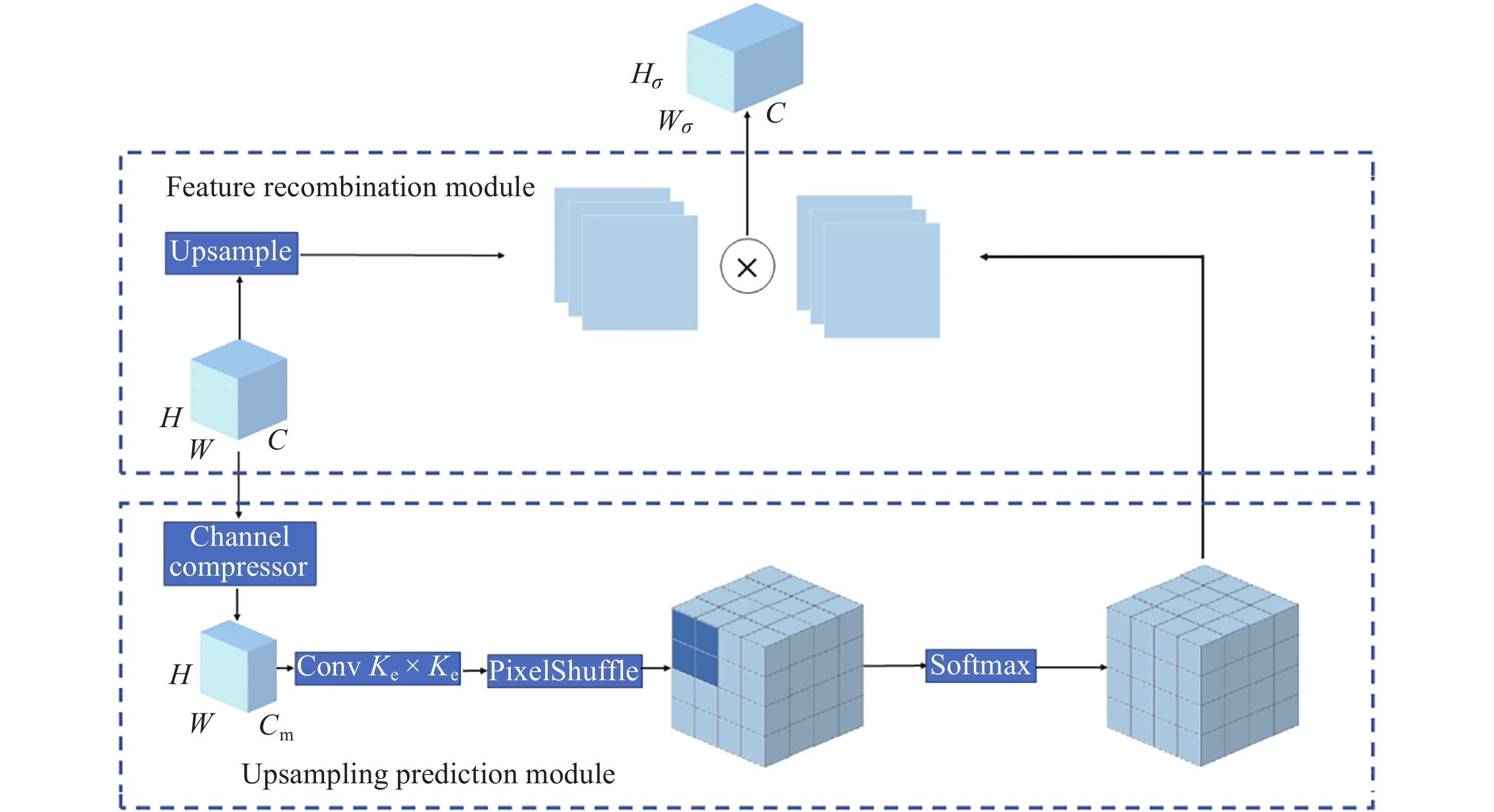
SHI W Z, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1874-1883
|
| [35] |
WANG J Q, CHEN K, XU R, et al. CARAFE: Content-aware reassembly of features[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3007-3016
|
| [36] |
ZHANG R. Making convolutional networks shift-invariant again[C]//Proceedings of the 36th International Conference on Machine Learning. Long Beach: PMLR, 2019: 7324-7334
|
| [37] |
AZULAY A, WEISS Y. Why do deep convolutional networks generalize so poorly to small image transformations[OL]. arXiv preprint arXiv: 1805.12177, 2018. https://arxiv.org/pdf/1805.12177
|
| [38] |
WEISS K, KHOSHGOFTAAR T M, WANG D D. A survey of transfer learning[J]. Journal of Big Data, 2016, 3: (1): 1-40
|
Figures(9) / Tables(3)
Journal Introduction
ISSN 2097-7689 CN 11-1783/V
Copyright © Editorial Office of Chinese Journal of Space Science. 京ICP备08100722号
Supported by: Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: